

Gaming technology and the technology that supports it has come a long way. With more powerful GPUs in our devices than ever, revolutions in chip manufacturing, and efficiencies in calculations allow us to do incredible things like run ray tracing engines in real time, simulate realistic physics, and so much more. All of this work has huge impact on gaming and immersive experience, but outside of creative industries what can we do?
I've done a lot of work and learning around the metaverse. As part of this learning I've made worlds, designed objects, and learnt a lot about 3D rendering. One thing I did to support some of this research was to 3D model my own building for some experimentation around MetaHumans - more on that soon. Once I had a render of my bedroom behind my workstation, I uploaded it as a Teams camera background. After talking with a few people, I realised not everyone cottoned on that it was even a digital render (the real thing is much messier normally).
This gave me an idea.
If people can't really tell what's real once the stream has been compressed and sent over the internet, could a machine vision model? I've always been interested in synthetic data creation for machine vision, but usually my starting point has been something real, like a photograph. What if we could make a working machine learning model with no real data at all?
The use case I chose was to find a tennis ball. Why? Well, it's about the size that our stretch RE1 robot can grab well, and it won't matter if it's dropped or bumps into anything, so, I was hoping the resulting model could be used to help the robot find and grab the tennis ball in the room. That's a challenge for another day though.
I started off with the 3D model of my room, and settled on the view from behind my workstation.

Then dropped a tennis ball onto the bed. (virtually). I wrote a script that can move the ball around the room, change the lighting conditions, and then automatically tag the ball location and upload it straight to Azure custom vision.
This uses the cycles engine, with a de-noised image generation capped at about 30 seconds on my machine. The beauty of this is you can easily change or limit the quality output, or scale your compute power to generate many thousands of quality pre-tagged images much faster than you could ever photograph a real scene and manually tag it, assuming you don't have to build an environment from scratch like I did here.

Playing around with the lighting conditions allows you to simulate lots of different conditions, which from my past research, really help to build a more resilient object detection model.
All that's left to do is to click train, and test the results!
The real thing
I used the minimum number of images required by Azure custom vision, just to push it to the max, but in reality with this method, you can keep adding camera views, lighting setups and noising to you heart's content.
First, let's test a real image from a similar viewpoint:
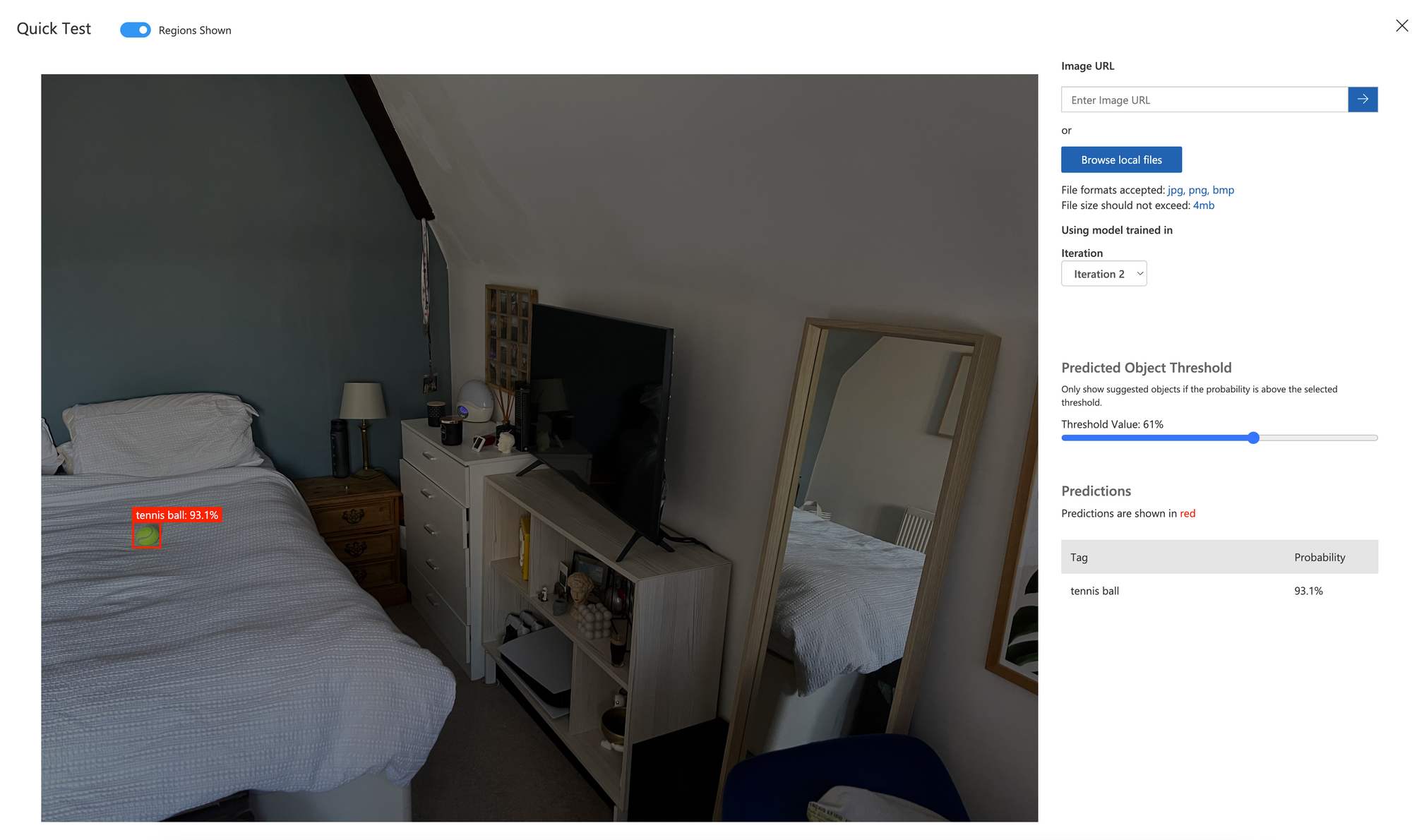
There we have it. The model has never seen a real tennis ball, but can identify the real one with 93.1% confidence, even with the lowest amount of synthetic data possibly generated.
What if we show it an image it wasn't trained on, with more objects than expected?
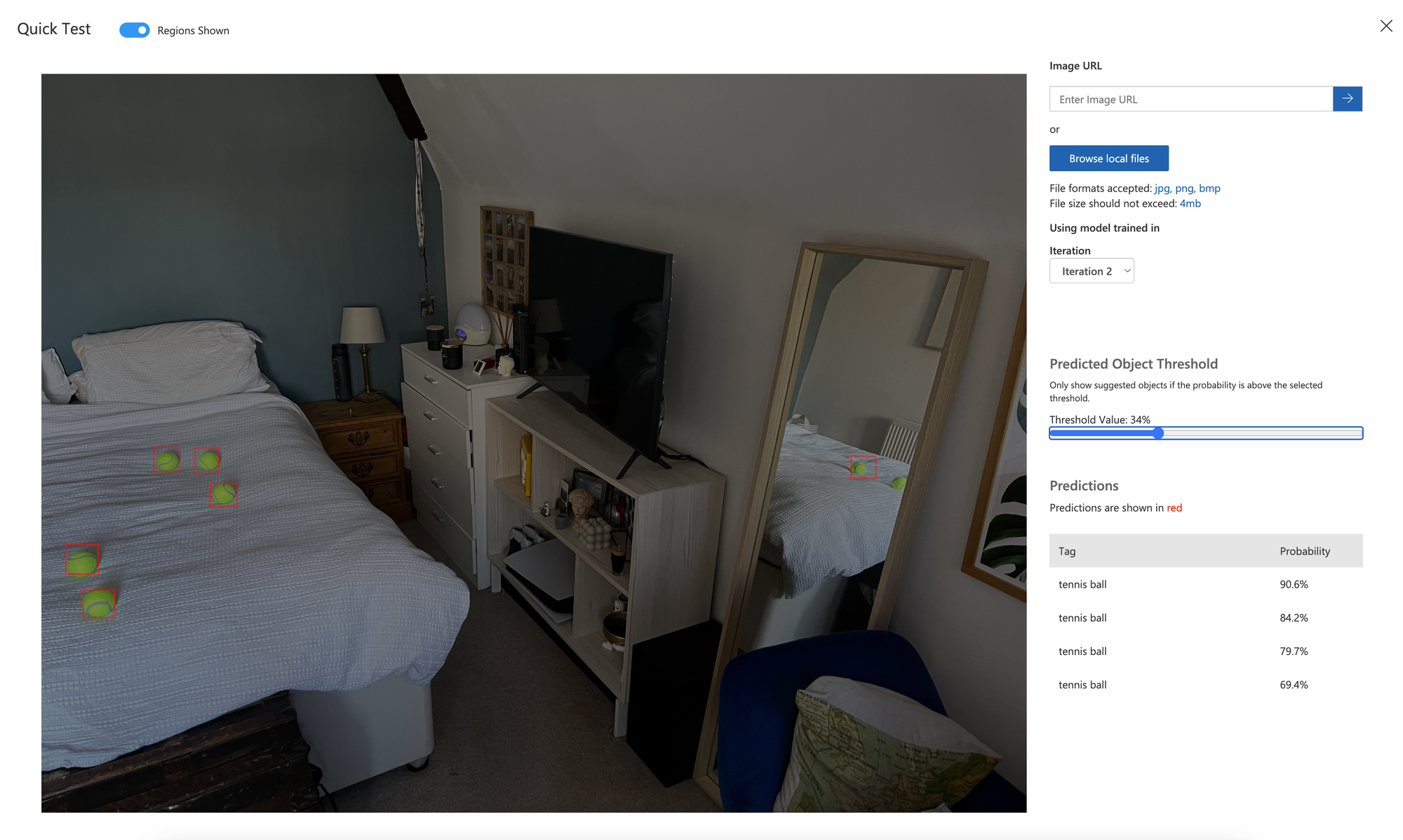
Well, we had to reduce the confidence limit, but we have still correctly identified all the tennis balls, even one from the reflection in the mirror.
Next, the real thing from a different viewpoint:
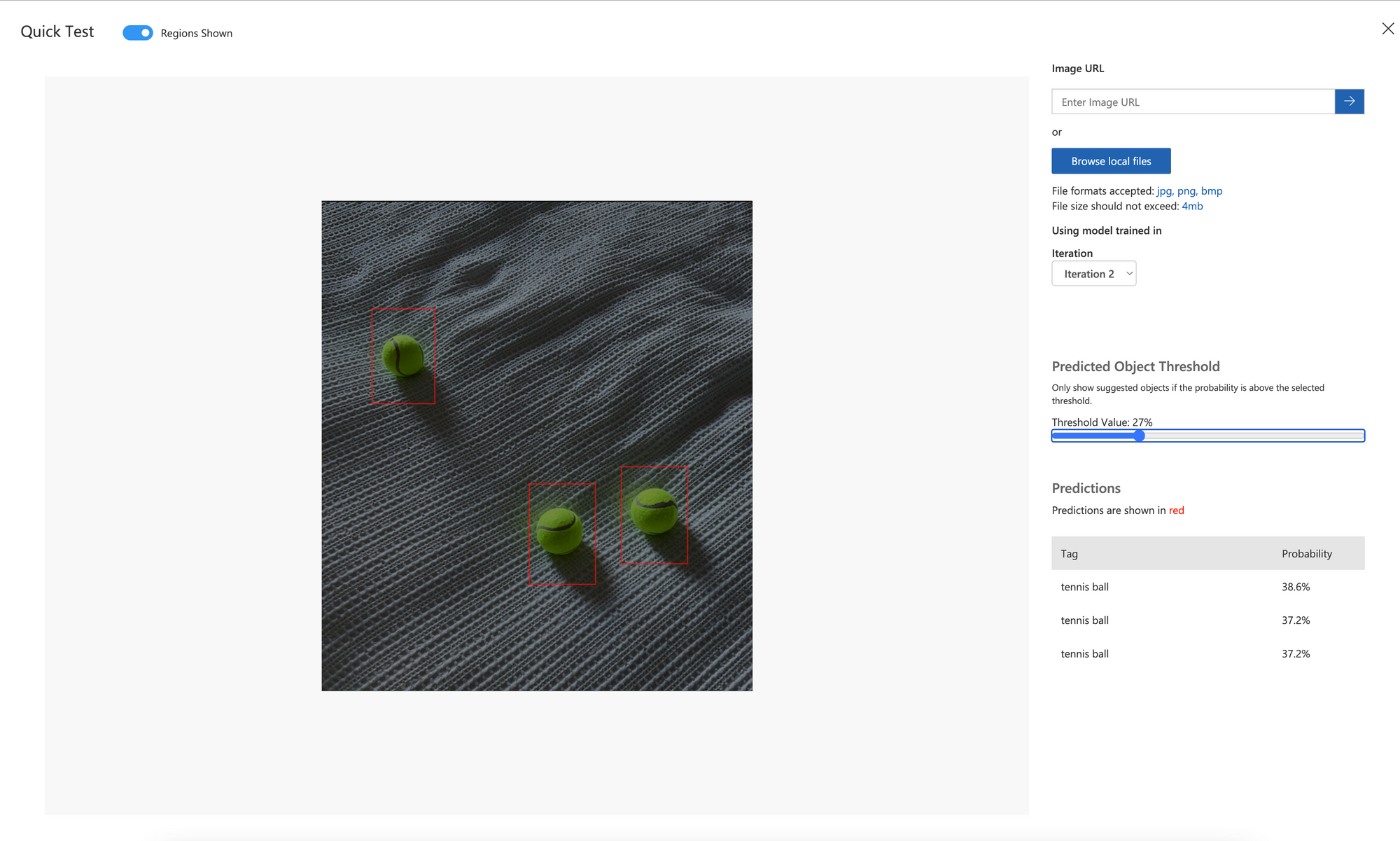
Not the highest confidences again, but still correct guesses - so this approach is still useable for a first pass where the context of the images meeds to change.
Finally, the same object but in a totally different context:
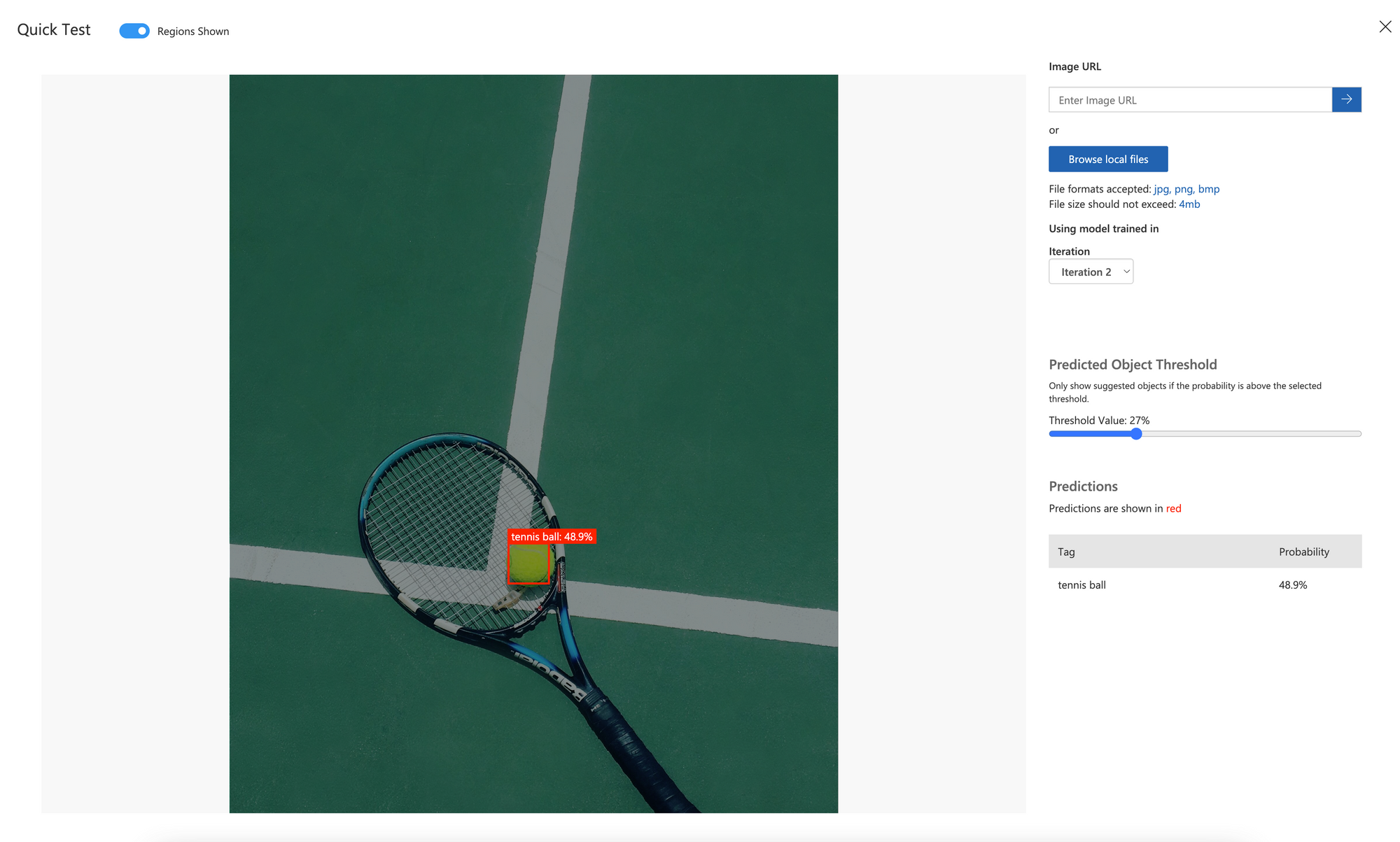
So, in a totally different context, it still works!
Imagine what we could do with many more renders, with no meed for any manual tagging, and looking at as many objects as we liked. There are great things going on in this sector from the likes of Unity as well, but for me, Blender gives the greatest flexibility on 3D rendering, with beautiful rendering available completely for free.


